比较好的建站程序枣庄网站seo
import requestsurl = 'https://movie.douban.com/top250'
response = requests.get(url)
# 查看结果
print(response)

在requests使用一文中我们有讲到,当状态码不是200时表示爬虫不可用,也就是说我们获取不到网页源代码。但是我们还是可以挣扎一下,不是说不可用就放弃了。爬虫时经常会遇到有些网站有反爬机制,为了能够请求成功该如何操作?那当然是把我们伪装成浏览器了!
那么如何把自己伪装成浏览器代替我们发送请求呢?pycharm有个字典Headers,我们需要在浏览器中找到键User-Agent对应的值
User-Agent:对应的值包含了浏览器、操作系统的各项信息。如果没有User-Agent,就相当于赤裸裸的去访问对方服务器,只要对方有反爬虫机制,就能发现你是爬虫。
在浏览器中打开想要爬取的网站,右键 --> 检查然后如下图操作:
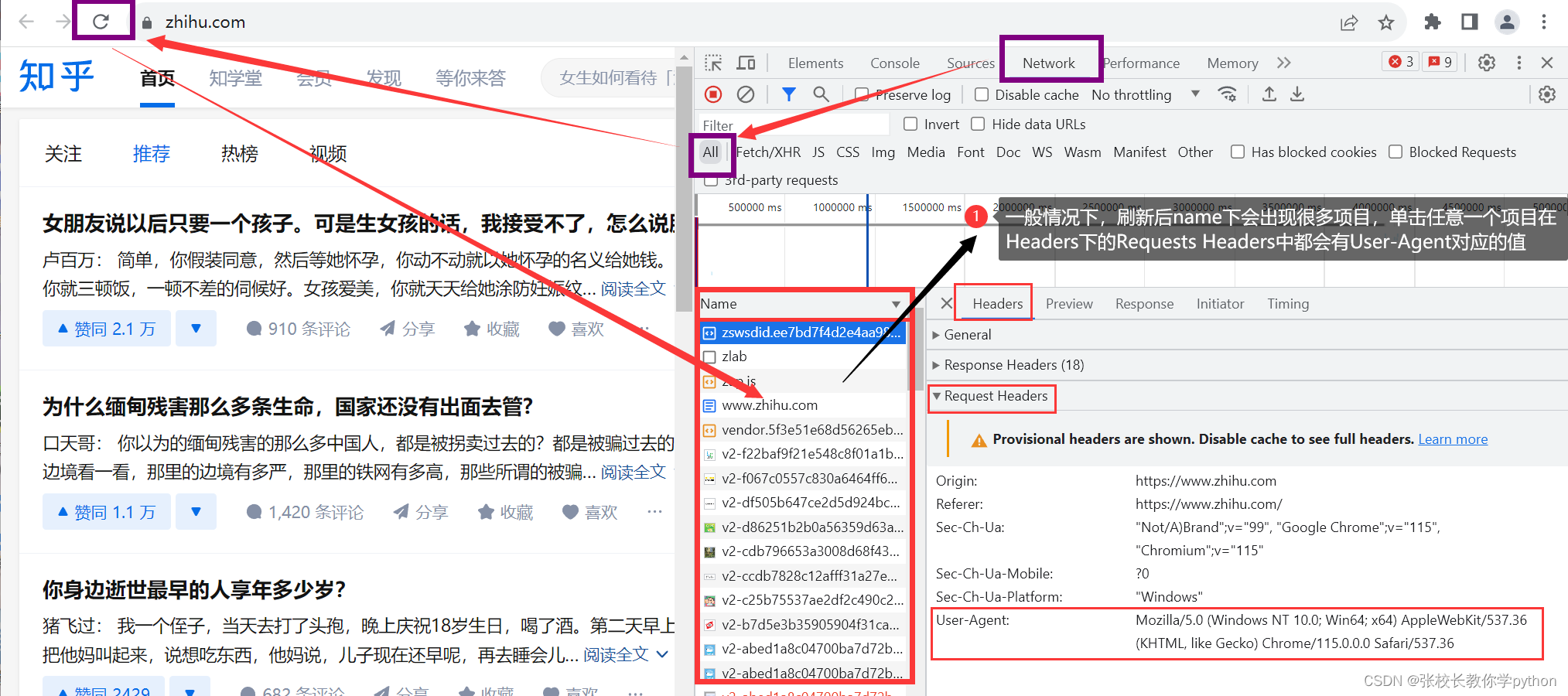
也有的网站刷新后出现的项目很少,甚至点开没有User-Agent对应的值,但是有一个项目里面一定有 : 项目名跟网站地址很相近的项目中。例如在本例中名为www.zhihu.com的项目里一定含有。
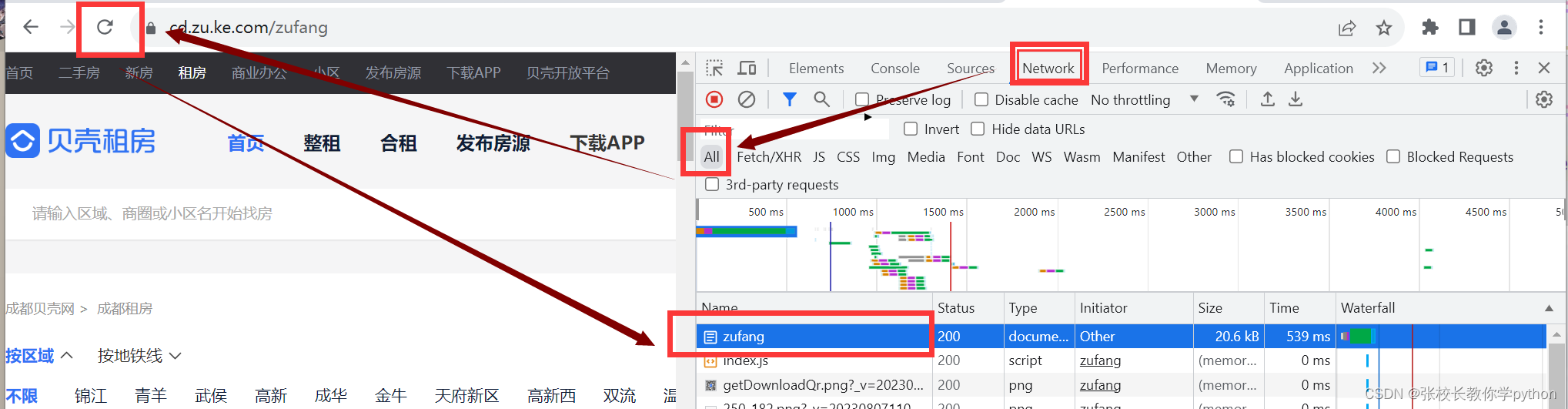
在以贝壳租房为例,打开网页后,右键 --> 检查,在项目名为zufang中一定含有User-Agent对应的值
获取键user-agent对应的值后,我们把键与值写入字典Headers中
import requests# 1. 浏览器伪装
url = 'https://movie.douban.com/top250'
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
# 获取响应结果
response = requests.get(url, headers=headers)
# 查看状态码
print(response.status_code) # 200
# 获取网页源代码
# print(response.text)